
18.6. jsem měl možnost přednášet na SEO Restartu s tématem automatizace analýzy klíčových slov. Jelikož jsem na pódiu nešel do hloubky a nepopisoval ono řešení, tak jsem pro vás připravil tento komplexní návod, který vás provede mnou popisovaným řešením.
Obsah článku:
V roce 2023 jsem spustil klub přátel pokročilého SEO & Discord kde začínám publikovat o pokročilejším SEO. Můžete očekávat, že tam projdu do větší hloubky technické SEO, data a nasdílím skripty, které běžně využívám k automatizaci SEO…
… zároveň půjdeme více do hloubky i co se týče Google Search Console a můžete očekávat informace z mých projektů. Aktuálně zaváděcí cena 10$ / měsíčně. Je to pro mě místo kde se mohu více věnovat SEO a sdílet vychytávky ze svých projektů. 🙂
Možnosti automatizace
Proces tvorby a přístup k analýze klíčových slov je vždy téměř stejný. Vždy začínáme sběrem dat, následně přejdeme k clusterizaci, průběžnému čištění, klasifikaci a na závěr provedeme interpretaci.

Bohužel se často věnujeme sběru a transfomraci dat, aniž bychom se věnovali tomu podstatnému a to interpretaci dat, nalezení souvislostí a definice dalších úkolů, které klienti skutečně ocení. Není nic horšího, než když klient dostane analýzu klíčových slov bez souvislostí a dalších informací a následně neví, co dělat dál.

Automatizací jednoduchých úkolů v analýze klíčových slov zkrátíme čas, který musíme věnovat například clusterizaci i klasifikaci a ten věnovat do interpretace, kterou klient skutečně ocení.
A to by měl být cíl automatizace tvorby analýzy klíčových slov. Měli bychom získat čas, který můžeme věnovat práci na výstupu případně zapracování konkrétních dalších kroků.
Clusterizace
V rámci clusterizace jsem se rozhodl zopakovat teorii, prerekvizity a následně vám ukázat všechna řešení, díky kterým můžete clusterizaci vyřešit. Schválně vám ukáži i staré řešení, abyste mohli srovnat staré versus nové řešení.
Kapitoly clusterizace:
- Princip
- Prerekvizity
- Aktuální řešení
- Řadící řešení
- Skriptovací řešení
Princip
Clasterizace je jednoduchá činnost v rámci které se snažíte sjednotit slova, které říkají to samé a ve výsledném datasetu by vás mohly mást. A nepřidají vám žádnou přidanou hodnotu.
Ve výsledku chcete spojit následující slova:
- krátké letní šaty
- letní šaty krátké
- šaty letní krátké
- šaty krátké letní
- letní krátké šaty
- krátké šaty letní
- kratke letni saty
- letni saty kratke
- saty letni kratke
- saty kratke letni
- letni kratke saty
- kratke saty letni
Do jednoho, které bude tuto skupinu reprezentovat. Jako reprezentanta ve většině případů hledáme gramaticky správné nebo nejhledanější slovo.
Prerekvizity
Clasterizace stojí a padá na mocném nástroji OpenRefine a jeho funkce Cluster and Edit. Aby vám mohl fungovat OpenRefine, budete potřebovat Javu a zároveň budete potřebovat dataset klíčových slov s hledaností z nástroje Marketing Miner, který nám dává data o hledanosti na základě click stream dat.
OpenRefine – http://openrefine.org/download.html
Java – https://java.com/en/download/
Pozor Java je obecně past vedle pasti co se týče Open Refine a musíte dát pozor jakou verzi stahujete. Dobrý návod o tom napsal Pavel Ungr na svém blogu.
Marketing Miner – https://www.marketingminer.com/cs
Click stream hledanost je podstatná, protože pouze na jejichž základě lze kvalitně rozhodnout, jaké slovo je z clastru nejhledanější a to využít.
Aktuální řešení
Klasickou klasterizaci aktuálně děláme pomocí funkce Cluster and Edit v Open Refine, kdy si rozkliknete sloupec klíčových slov a na něm spustíte zmiňovanou funkci. Následně vybíráte správné zástupce clusteru.
Konkrétní kroky ruční clusterizace:
- Připravte si projekt
- Otevřete si funkci Cluster and Edit
- Určete jednotlivé clustry
1) Připravte si projekt

Nahrajte projekt, který bude obsahovat sloupec: “klíčové slovo” a “hledanost” do nástroje OpenRefine. Pojmenování sloupců je v případě tohoto řešení nedůležité.
2) Otevřete si funkci Cluster and Edit
Abyste otevřeli funkci Cluster and Edit, tak si otevřete nastavení sloupce, nechte si rozjet “Edit cels” a klikněte na “Cluster and edit…”.

Jakmile kliknete na funkci “Cluster and edit”, tak se vám otevře pop-up, ve kterém můžete zvolit funkci pro určení clustrů, navržené clustry a “šoupátka” pro ořezání velikosti datasetu.

3) Určete jednotlivé clustry
Ve sloupečku “Values in Cluster” jsou hodnoty, které OpenRefine označil za podobné, dle klíče, který jsem popsal v teorii clusterizace.

Jak můžete vidět, tak za zástupce prvního clustru označil OpenRefine “hodiny nastenne”, avšak clustr by pravděpodobně lépe zastupoval gramaticky správný nebo hledanější skupina.
Abyste se rozhodli a vybrali správného zástupce, tak potřebujete vidět další informace. Stačí “najet” kurzorem na jeden sloupec, díky čemuž se vám objeví tlačítko “Browse this cluster”.

Po rozkliknutí se vám otevřou v nové záložce vyfiltrované hodnoty clastru a vy můžete rozhodnout, jaké slovo vyberete jako zástupce clastru.

Ve vzorovém případě bych se rozhodnul pro “nástěnné hodiny”, jelikož mají největší hledanost a to 3 800 hledání měsíčně. Podobným způsobem to musíte udělat u každého z vybraných clastrů. Díky čemuž si budete na 100 % jisti, že sedí.
Proč je toto řešení špatné?
Toto řešení vnímám jako špatné z toho důvodu, že musíte ručně procházet všechny clustry. V případě menší analýzy klíčových slov může jít o 2 hodiny, ale když máte třeba 5 000 clastrů, tak vám to již nějakou dobu potrvá.
Řadící řešení
Pojďme se podívat na první rychlé řešení, které provede clusterizaci během několika málo sekund a které stojí na metodě řazení, které OpenRefine nabízí. V rámci tohoto řešení nemusíte o ničem rozhodovat, jen si musíte dát pozor, že vše bude správně nastavené.
1) Připravte si projekt
Stejně jako v předchozím řešení, musíte založit nový projekt v OpenRefine, který by měl opět obsahovat sloupec “Keyword” a “Search Volume”.
2) Vytvořte sloupec zálohy
Abychom se v budoucnosti dostali k nejhledanějšímu klíčovému slovu ze skupiny, tak si musíme vytvořit sloupec zálohy, do kterého umístíme původní klíčová slova.

Nový sloupec můžete libovolně pojmenovat a chcete do něj uložit stejná klíčová slova, jako jsou ve sloupci “Keyword”. Tudíž nic neměňte a rovnou můžete nový sloupec založit.

Nový sloupec založíte kliknutím na OK.
3) Seřaďte od nejhledanějšího po nejméně hledaný
Jakmile vytvoříte sloupec zálohy s názvem Keyword-bu, takže seřaďte dataset dle hledanosti, který vám zajistí, že se bude do clastru pravděpodobně nastavovat nejhledanější slovo z clastru.

Jakmile kliknete na tlačítko “Sort…”, tak na vás vyskočí vyskakovací okno, kde musíte nastavit, že chcete srovnávat čísla od největšího po nejmenší.
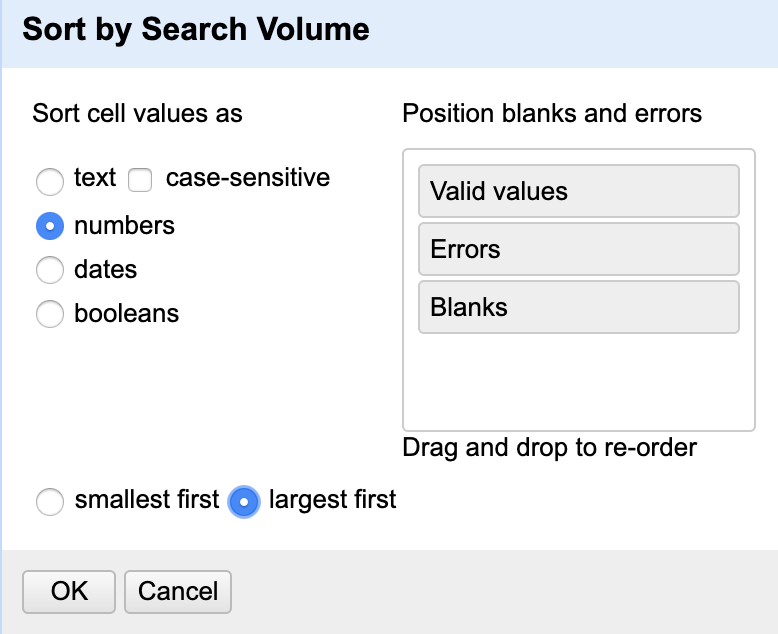
A následně nastavte seřazení tak, aby se dataset “přeindexoval”, což vám umožní rozbalovací nabídka “Sort” a výběr “Reorder rows permanently”.
4) Proveďte clasterizaci
Nyní na sloupečku “Keyword” spusťe funkci “Cluster and Edit” a zobrazí se vám již známý pop-up, kde jednoduše můžete nastavit “Select all” a následně stačí provést clusterizaci pomocí “Merge Selected & Close”
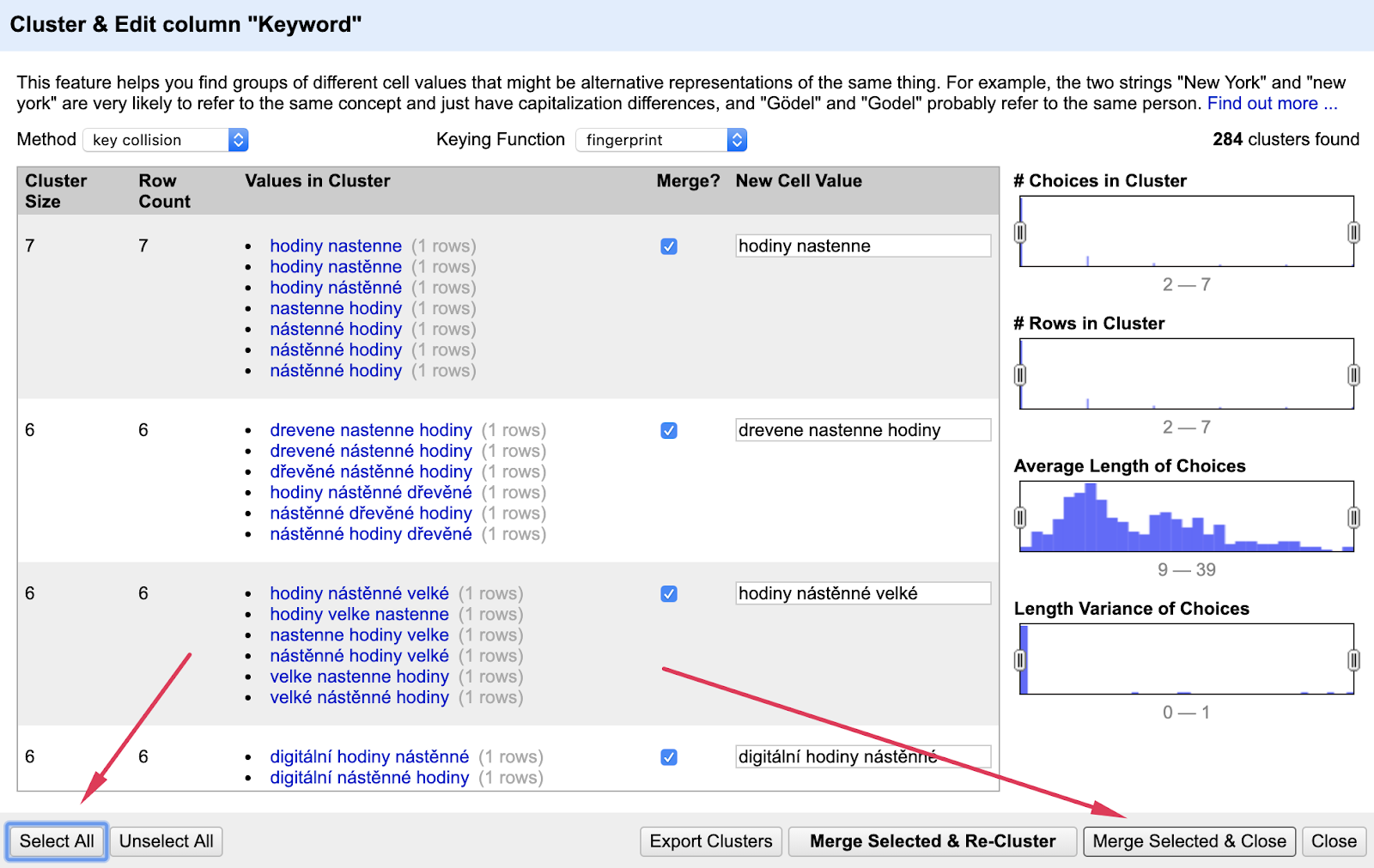
Na pozadí se provede to, že se automaticky vybere náhodná hodnota bez toho anižbyste museli cokoliv kontrolovat a nastavovat. Onu selekci nejhledanějšího provedeme až v kroku 5.
5) Seřaďte od A – Z + Seřaďte dle hledanosti
Nyní proveďte seřazení od A – Z na sloupci “Keyword” díky čemuž se vám jednotlivé clustry dají pěkně “pod sebe”. A stejně tak nastavte sekundární řazení dle hledanosti. Následně projekt permanentně seřaďte.
Jakmile provedete seřazení, tak využijte funkce blank down, která smaže ony hodnoty a zmeňme tak jednotlivé řádky na záznamy.

Po funkci Blank down by měl testovací dataset vypadat následovně. Ano, dataset není pročištěný, jelikož jsem jej náhodně vybral z Marketing Mineru pro demonstraci řešení.

6) Ruční kontrola
Nyní bych vám doporučil ruční kontrolu a projít si jednotlivé prázdné řádky a zkontrolovat, jestli je na prvním místě vždy nejhledanější klíčové slovo. V následujícím kroku budeme muset zachovat původní hodnoty, abychom se k nim mohli kdykoliv v budoucnosti vrátit.
7) Sečtěte hodnoty
Nyní sjednoťte sloupce „Keyword-bu“ i „Search Volume“ do jednoho, díky čemuž budeme moc jednoduše uchovat všechny slova v clustru i sečíst hledanosti. Klikněte na Keyword-bu a vyberte „Join multi-valued cells…“

Jakmile se vám zobrazí patřičný pop-up, tak bude nutné vyplnit znak pro rozdělení slov. Za mě vám mohu doporučit znak ¤ (Alt + 15), který se ve vašem datasetu nebude pravděpodobně nikdy zobrazovat.
V případě hledanosti můžete v klidu spojit dle čárky, tam nám to ničemu vadit nebude. 🙂 Sečtení hledanosti provedete pomocí tohoto příkazu v GRELu:
forEach(value.split(','),v,v.toNumber()).sum()8) Smažte prázdné hodnoty
Nyní vám již stačí vybrat si „Customized facets“ a „Facet by blank“ a všechny hodnoty, které obsahuji True smazat.

Následně vyberte hodnoty True a ty smažte pomocí „Remove all matching rows“

Z praxe
Pokaždé, když jsem zkoušel toto řešení, tak jsem se více či méně zasekal na onom řadícím systému, avšak věřím, že když budete postupovat dle návodu, tak to zvládnete.
Skriptovací řešení
Jak již názvem napovídá, tak druhou variantou řadící metody je skriptovací řešení, které rozhoduje o Clusterizaci na základě „skriptu“. Původně jsme si chtěli funkce v OpenRefine „ohnout“ a „doprogramovat“, avšak nakonec to nebylo třeba.
Jediné, co musíte dodržet je správné založení projektu s korektním pojmenováním sloupců a o zbytek se postará OpenRefine.
1) Připravte si projekt
Základem je připravit si projekt, který bude mít dva sloupce. V tom prvním bude „Keyword“ a ve druhém „Search“. Jako hodnotu sloupce „Search“ vám výrazně doporučuji využít hledanosti z Marketing Mineru, protože jsou přesnější.

Když nedojde ke korektnímu pojmenování, tak vám následující skript nebude fungovat, což by byla škoda.
2) Vytvořte nový sloupec Keyword-bu
Opět jako v předchozím principu vytvořte nový sloupec Keyword-bu, ze kterého budeme následně vybírat ono správné klíčové slovo.
3) Proveďte clasterizaci
Nyní nad sloupečkem Keyword spusťte funkci Cluster and edit a rovnou zaklikněte, že to chcete nastavit tak, jak vám hodnoty do skupin navrhl OpenRefine. Je úplně v pohodě, že ty skupiny nebudou přesné, onu přesnost vykouzlíme skriptem.

4) Spusťte skript
Nyní stačí využít magické funkce Apply a umístit do ni následující kód, který vám na základě námi připravených sloupců na clusterizaci provede výběr toho nejhledanějšího slova a to uloží v novém sloupci.
[
{
"op": "core/row-reorder",
"description": "Reorder rows",
"mode": "row-based",
"sorting": {
"criteria": [
{
"errorPosition": 1,
"caseSensitive": false,
"valueType": "string",
"column": "Keyword",
"blankPosition": 2,
"reverse": false
}
]
}
},
{
"op": "core/blank-down",
"description": "Blank down cells in column Keyword",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Keyword"
},
{
"op": "core/multivalued-cell-join",
"description": "Join multi-valued cells in column Keyword-bu",
"columnName": "Keyword-bu",
"keyColumnName": "Keyword",
"separator": "☼"
},
{
"op": "core/multivalued-cell-join",
"description": "Join multi-valued cells in column Search",
"columnName": "Search",
"keyColumnName": "Keyword",
"separator": ", "
},
{
"op": "core/text-transform",
"description": "Text transform on cells in column Search using expression value.toString()",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Search",
"expression": "value.toString().replace('.0', '')",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/column-addition",
"description": "Create column Index at index 3 based on column Search using expression jython:array = value\narray = array.split(',')\n\nx = 0\nmax = 0\nindex = 0\n\nwhile x < len(array):\n array[x] = int(array[x])\n if max < array[x]:\n max = array[x]\n index = array.index(max)\n x = x + 1\n\nreturn index",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"newColumnName": "Index",
"columnInsertIndex": 3,
"baseColumnName": "Search",
"expression": "jython:array = value\narray = array.split(',')\n\nx = 0\nmax = 0\nindex = 0\n\nwhile x < len(array):\n array[x] = int(array[x])\n if max < array[x]:\n max = array[x]\n index = array.index(max)\n x = x + 1\n\nreturn index",
"onError": "set-to-blank"
},
{
"op": "core/column-removal",
"description": "Remove column Keyword",
"columnName": "Keyword"
},
{
"op": "core/column-addition",
"description": "Create column Keyword at index 1 based on column Keyword-bu using expression grel:forEach(value.split('☼'),v,v).get(cells['Index'].value)",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"newColumnName": "Keyword",
"columnInsertIndex": 1,
"baseColumnName": "Keyword-bu",
"expression": "grel:forEach(value.split('☼'),v,v).get(cells['Index'].value)",
"onError": "set-to-blank"
}
]Výsledný projekt bude aktuálně vypadat takto, tudíž si můžete zkontrolovat, že je vše naklasifikované správně.
V roce 2023 jsem spustil klub přátel pokročilého SEO & Discord kde začínám publikovat o pokročilejším SEO. Můžete očekávat, že tam projdu do větší hloubky technické SEO, data a nasdílím skripty, které běžně využívám k automatizaci SEO…
… zároveň půjdeme více do hloubky i co se týče Google Search Console a můžete očekávat informace z mých projektů. Aktuálně zaváděcí cena 10$ / měsíčně. Je to pro mě místo kde se mohu více věnovat SEO a sdílet vychytávky ze svých projektů. 🙂
5) Zkontrolujte řešení
Kontrolu můžete provést pouhým okem, kdy se musíte podívat na hodnoty ve sloupci Search a následně se podívat na hodnotu ve sloupci Index. V OpenRefine se index počítá stejně jako téměř v každém programocím jazyku od nuly, tudíž nula znamená první výskyt v řetězci.

Na obrázku výše je vidět, že OpenRefine určil všude, že je nejhledanější vždy to první slovo a tedy jej i vybral. V tomto případě jde o naprosto očekávané chování, které je správné.
Jakmile budete mít zkontrolováno, tak spusťte následující skript, kterým dataset dočistíte a dostanete jeje do vámi oblíbené podoby.
[
{
"op": "core/text-transform",
"description": "Text transform on cells in column Search using expression grel:forEach(value.split(','),v,v.toNumber()).sum()",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"columnName": "Search",
"expression": "grel:forEach(value.split(','),v,v.toNumber()).sum()",
"onError": "keep-original",
"repeat": false,
"repeatCount": 10
},
{
"op": "core/column-removal",
"description": "Remove column Index",
"columnName": "Index"
},
{
"op": "core/row-removal",
"description": "Remove rows",
"engineConfig": {
"facets": [
{
"type": "list",
"name": "Keyword-bu",
"expression": "isBlank(value).toString()",
"columnName": "Keyword-bu",
"invert": false,
"selection": [
{
"v": {
"v": "true",
"l": "true"
}
}
],
"selectNumber": false,
"selectDateTime": false,
"selectBoolean": false,
"omitBlank": false,
"selectBlank": false,
"omitError": false,
"selectError": false
}
],
"mode": "row-based"
}
},
{
"op": "core/column-reorder",
"description": "Reorder columns",
"columnNames": [
"Keyword",
"Keyword-bu",
"Search"
]
}
]Zrychlená varianta
Jak bylo možné vidět, tak tuto cestu lze provést skutečně na pár kliků díky Extract and Apply, které zajistí, že se vše provede správně.
Jestliže tuto funkcionalitu neznáte a chtěli byste si umět dlouhodobě šetřit práci, tak vám doporučuji navštívit školení Filipa Podstavce, kde tuto funkcionalitu popisuje.
Z praxe
Tato varianta je z mého pohledu naprosto nejspolehlivější, protože funguje jak „Švýcarské hodinky“. A proběhne skutečně během pár vteřin maximálně minut.
Srovnání jednotlivých řešení
Z právě popsaných řešení, bych zvolil jako vítěznou variantu tu, která běží pomocí skriptů. Jelikož obsahuje kontrolní mechanismus, díky kterému je možné vrátit se zpět v procesu a zanalyzovat, jestli se vše provedlo správně případně ji můžete používat pomocí tlačítka „Apply“.

Avšak vám doporučuji otestovat všechny možné řešení a vybrat si z nich to nejlepší. Avšak za mě je favorit skriptová metoda. U nás v Taste Medio ji využíváme již od října a ušetřila nám přes 400 hodin, které jsme mohli vynovat do lepších datasetů a hlavně interpretace. 🙂
Klasifikace
- Princip
- Prerekvizity
- Aktuální řešení
- ML + Reconcile.csv
Princip
Princip klasifikace popsal již Marek Prokop v roce 2012, přičemž se od té doby téměř nic nezměnilo. V podstatě jde o to, že se snažíte jednotlivá klíčová slova zařadit do klasifikačních schémat, díky čemuž se vám otevře nový, podrobnější pohled na klíčová slova a to hezky ve skupinách.
Prerekvizity
Klasifikaci pomocí umělé inteligence za nás udělá Marketing Miner. Zbytek budeme provádět opět v mocném nástroji OpenRefine tudíž budete potřebovat Javu a zároveň budete potřebovat i Reconcile.csv server.
OpenRefine – http://openrefine.org/download.html
Reconcile.csv – http://okfnlabs.org/reconcile-csv/.
Java – https://java.com/en/download/
Marketing Miner – https://www.marketingminer.com/cs
Aktuální řešení
Věřím, že klasifikace je v naší SEO komunitě rozšířenější, než clusterizace datasetu, tudíž jsem se ji rozhodl, že ji nezpracuji, jako aktuální clusterizaci. Jestliže však ve vašich analýzách klíčových slov klasifikaci neděláte, tak vynikající video o tom, jak ji udělat připravit Marketing Miner.
Je toto řešení špatné?
Toto řešení klasifikace analýzy klíčových slov není vyloženě špatné, jen je velmi zdlouhavé a nabízí se tedy automatizace tohoto procesu. Dlouho bylo toto řešení jediné možné, avšak na začátku tohoto roku se stalo něco, co začalo fungovat. 🙂
V roce 2023 jsem spustil klub přátel pokročilého SEO & Discord kde začínám publikovat o pokročilejším SEO. Můžete očekávat, že tam projdu do větší hloubky technické SEO, data a nasdílím skripty, které běžně využívám k automatizaci SEO…
… zároveň půjdeme více do hloubky i co se týče Google Search Console a můžete očekávat informace z mých projektů. Aktuálně zaváděcí cena 10$ / měsíčně. Je to pro mě místo kde se mohu více věnovat SEO a sdílet vychytávky ze svých projektů. 🙂
Reconcile.csv + Využití umělé inteligence
Minulý rok se na SEO Restartu řešilo párování chybových URL adres na nové pomocí reconcile.csv tedy vlastnímu serveru na reconcilaci dat. Tento server páruje data dle podobnosti klíčových slov.
Například slovo Plzeň a Plzni k sobě bude blíž, než Plzeň a Praha. Této vlastnosti můžeme využít právě na párování slov do skupin. Tudíž si vytvoříme databázi, na kterou budeme následně párovat klíčová slova.
Toto řešení by však nebylo tak unikátní a zrychlující čas, kdyby v Marketing Mineru nevytvořili umělou inteligenci, která vytvoří schémata a hodnoty za vás. Na vás je pak výstup projít, doplnit a následně můžete poslat podklad do reconcilačního serveru, který provede klasifikaci za vás.

Jak tedy provést klasifikaci v podání umělé inteligence a reconcile.csv?
- Pošlete data do Marketing Mineru
- Použijte čištění dle similiarity
- Připravte data pro reconcile.csv
- Spusťte reconcile.csv a proveďte párování
- Projděte si výsledek
- Pokračujte s interpretací
1) Pošlete data do Marketing Mineru
S tímto krokem si nejsem přesně jist, jak to kluci v Marketing Mineru do SEO Restartu domyslí, tudíž tento bod nechávám prozatím otevřený. Každopádně je nutné poslat vaše data do Marketing Mineru.
Umělá inteligence si dataset projde a pokusí se v něm najít různá schémata (obce, barvy, velikosti, umístění, produkty,…) do kterých bude následně vybírat jednotlivé hodnoty.
Zároveň budete moci využívat takzvaného nástroje Similarity, kdy nadefinujete klíčová slova a Marketing Miner srovná obsah datasetu se zadanými kořenovými slovy a na základě vygenerovaných skupin si můžete jednoduše pročistit dataset.

Pro ukázku budu následující body ukazovat na datasetu, který jsem dostal přímo od Filipa a který byste do budoucnosti měli dostávat i z Marketing Mineru. Tento dataset stojí na naší vzorové analýze klíčových slov.
2) Vyčistěte dataset pomocí similarity
Ona similarita může být pro vás vynikajícím nástrojem na čištění analýzy klíčových slov. Kdy pomocí naučené inteligence lze odstranit klíčová slova, která nejsou relevantní.
Na následujícím screenu je možné vidět sloupec druhý sloupec similarity, který ukazuje obsahovou vzdálenost dotazu od klíčového slova hodiny.

Na základě „numeric facetu“ si můžete nechat vygenerovat graf o tom, jak jsou jednotlivá klíčová slova vzdálená od kořenového slova hodiny.

Jak je možné vidět, tak hodnoty podobnosti klíčových slov se párují do takzvané gausovy křivky, což bych považoval za pohodový vývoj. Na co bych se teď snažil podívat je minimum a konkrétně se podívat, co dataset obsahuje za slova.
Jakmile snížím hranici na nejvíce vzdálené, tak mohu vidět následující klíčová slova:

Díky tomuto můžete jednoduše smazat naprosto nerelevantní fráze, které ve vaší analýze nemají co dělat. Avšak nic nenahradí pěkně poctivé ruční čištění. A stejně tak vám doporučuji projít dataset před tím, než něco smažete. Může jít o vzor, o kterém jste doposud nevěděli.
3) Připravte data pro reconcile.csv
Jakmile budete mít dataset vaší analýzy klíčových slov pročištěný, tak můžeme přijít k přípravě podkladu pro reconcile.csv. Z klasifikace, kterou mi vytvořil Marketing Miner se snažím vytvořit podobnou tabulku, kde si jeho skupiny rozvrhnu pěkně pod sebe.

Tuto tabulku se pak snažím doplnit pomocí word facetu, kdy ji doplním o klíčová slova, která mohla umělé inteligenci uniknout a následně tuto tabulku přetavím do projektu v OpenRefine.
Později se totiž budu na tuto tabulku dotazovat, abych získal informace o skupinách. A provedl tak rozdělení do patřičných sloupců. Takže je v pohodě, když si připravíte data v OpenRefine.

Jakmile dostanete data do OpenRefine, tak je dobré převést klíčové slova do varianty bez kapitálek a přidání sloupce ID. To lze provést jednoduše pomocí tlačítka „Apply“. Pozor název prvního sloupce musí být KW, aby vše správně fungovalo.
[
{
"op": "core/column-addition",
"description": "Create column Normalizace at index 1 based on column KW using expression grel:value.toLowercase()",
"engineConfig": {
"facets": [],
"mode": "row-based"
},
"newColumnName": "Normalizace",
"columnInsertIndex": 1,
"baseColumnName": "KW",
"expression": "grel:value.toLowercase()",
"onError": "set-to-blank"
},
{
"op": "core/column-addition",
"description": "Create column id at index 2 based on column Normalizace using expression grel:rowIndex + 1",
"engineConfig": {
"facets": [],
"mode": "record-based"
},
"newColumnName": "id",
"columnInsertIndex": 2,
"baseColumnName": "Normalizace",
"expression": "grel:rowIndex + 1",
"onError": "set-to-blank"
}
]Po aplikování tohoto pravidla se stane to, že se vytvoří nový sloupeček „normalizace“ a „id“.

Tyto nové sloupečky využijeme, jako podklad pro reconcile.csv server. Abyste tam dostaly správná data, tak musíte kliknout na možnosti exportu a kliknout na templating.
Do šablony musíte vyplnit následující parametry:

Snažíme se vytvořit .csv soubor, který nahrajeme do serveru a ten se bude snažit tato slova párovat na vaše klíčová slova. Je nutné zachovat tento formát, jinak reconcile.csv server nebude fungovat.
4) Spusťte reconcile.csv
Jakmile budete mít stažený (tlačítko Export) .csv soubor, tak můžete přejít ke spuštění serveru, který spustíte jednoduchým příkazem.
java -Xmx8g -jar "C:\reconcile\reconcile-csv-0.1.2.jar" "C:\reconcile\vie5.csv" "keyword" "id"Kód pro spuštěný je jednoduchý, stačí vyměnit jednotlivé parametry dle vašeho počítače. Jednotlivé parametry, jsou následující:
- „C:\reconcile\reconcile-csv-0.1.2.jar“ – Stažený server
- „C:\reconcile\seorestart.csv“ – Umístění datasetu z OR
- „keyword“ – Název sloupce pro klíčové slovo
- „id“ – ID klíčového slova
Jestli vás budou zajímat další informace k Reconcile.csv serveru, tak doporučuji článek od Zdeňka Nešpora, který uvnitř řeší veškeré problémy.
Jakmile vám bude fungovat váš Reconcile.csv server, tak se přesuňte do projektu, co máte v OpenRefine a vytvořte nový sloupec pro klíčová slova (jako v předchozích krocích záloha)

Pro párování bude nutné rozdělit obsah sloupce „Keywords“ dle mezery, aby na každém řádku bylo pouze jedno klíčové slovo. A to z toho důvodu, že v naší databázi máme klíčová slova, která jsou složena z jednoho slova.
Využijeme k tomu funkci „Split multi-valued cells…“ spuštěnou na sloupci „Keywrods“

Jakmile na vás „vyskočí“ pop-up, tak v něm nestavte mezeru, jakožto separátor, díky čemuž rozdělíme slova do řádků dle mezery.

Díky rozdělení vám vznikne něco podobného:

Teď konečně spustíme párovací skript, který funguje na principu reconcilace. Takže klikněte najeďte na Reconcile a Star reconciling.

Jakmile na vás „vyskočí“ pop-up, tak stiskněte „Add Standard Service“, kam vložte tuto URL adresu, tedy adresu vašeho reconcilačního serveru. Myslím si, že by měla být: http://localhost:8000/reconcile

Jakmile se vám vytvoří nová reconcilační služba s názvem „CSV Reconciliation service“, tak klikněte na tlačítko „Start Reconciling“ a to vám spustí automatizované párování.
5) Projděte si výsledek
Jakmile doběhne Reconcilace do konce, tak se vám určitá část klíčových slov projektu napáruje. A zbytek klíčových slov bude pravděpodobně na vás.

Ono urychlení, které zde je se skrývá ve facetech. Většinou automaticky věřím pravděpodobnosti 0,85 – 1 a zde nechávám párovat všechna klíčová slova automaticky. Ostatně i na první pohled na následujícím obrázku můžete vidět, že se klíčová slova párují v pohodě.

Jakmile provedete napárování těchto klíčových slov, tak se doporučuji přesunout do segmentu 0,40 – 0,85 a následně začít postupovat dle word facetu.

A takto lze jednoduše spárovat většinu klíčových slov, které vám budu dávat smysl. Nebojte se omezovat databází, kterou pro vás vytvořil Marketing Miner případně vaše maličkost.
Nové hodnoty ve schématech můžete založit kliknutím na „Create new item“, díky čemuž vytvoříte nové hodnoty. Zpětně si je pak přiřadíte do schémat, kam dané skupiny budou patřit.
6) Zařazení do schémat
Na závěr budete muset uložit vygenerovaná schémata, což dokážete pomocí jednoduchého příkazu:
cell.recon.candidates[0].nameTento příkaz vám bude fungovat pouze na slova, která se vám podařilo připojit s vaší databází. Pro nově vytvořené skupiny si vytvořte nový sloupec.
Následně bude nutné si napojit skupiny z onoho projektu, který vznikl na začátku a obsahoval všechny hodnoty a jejich schémata. To provedete pomocí funkce cell.cross
cell.cross("ProjektsHodnotami", "SloupecHodnot")[0].cells["Schema"].valuePro hodnoty bez schémat tato schemata pomocí facetů budete muset jednoduše doplnit / dopsat a následně na základě jednotlivých hodnot ve sloupečku Schéma budete vytvářet nové sloupce, do kterých budete ukládat hodnoty klíčových slov. Díky čemuž vám vznikne zaklasifikovaná analýza klíčových slov.
Z praxe
Řešení umělé inteligence a reconcile.csv vás pravděpodobně ruční práce na 100% nezbaví. Avšak vám to podstatně ušetří čas a vy se budete moci věnovat těm důležitějším částem analýzy.
Závěr článku
Na závěr článku bych vám rád poděkoval za přečtení a budu rád, když začnete tyto principy využívat. A stejně tak budu rád, když se budete snažit tyto postupy překonat, vytvořit lepší a posunout nás dál.
Rozhodně se budu těšit na zpětnou vazbu a jestli vám tyto procesy ušetří čas, tak budu rád za další sdílení. A já jdu pracovat na další automatizaci, abych měl co prezentovat na SEOzrazu 2020, kam jsem byl pozván.
Velmi pekny clanok. Clusterizaciu som sa snazil riesit nejak podobne, dokonca aj upravou zdrojoveho kodu samotneho Open Refine, ale taketo jednoduche riesenie mi nenapadlo 🙂
Tiez by som dodal, ze Google ads v planovaci klucovych slov vytvara skupiny slov podla ich vyznamu, co sa priblizuje klasifikacii. Takze to moze tiez usetrit nejake hodiny z klasifikacie.
Ahoj Matůši,
úprava zdrojového kódu nás napadla, ale pak nám to přišlo poměr cena x výkon špatné, jelikož bychom se ochudili o aktualizace ne? 🙂 Jinak určitě to je taky cesta, jak si zjednodušit práci.
To sice ano, ale nemůžete to získat pro libovolně velký dataset pomocí API nebo se pletu? Jestli ano, tak by to mohlo být minimálně vyzkoušeníhodné. 🙂
Ahoj Martin,
prosim ta, kde najdem tu funkciu „apply“ v open refine? Nejako ju neviem najst.
Diky vopred za odpoved
Ahoj Miroslave,
funkce „apply“ se nachází v OpenRefine po kliknutí na tlačítko „Undo / Redo“ a následně se objeví vedle tlačítka „Extract“
Viz screen: http://prntscr.com/o5x9he
Dakujem velmi pekne, Martin.
Super článek, moc za něj díky! Vyzkouším…
Ahoj Martine,
kde jsi dostal tyto data „Z klasifikace, kterou mi vytvořil Marketing Miner se snažím vytvořit podobnou tabulku, kde si jeho skupiny rozvrhnu pěkně pod sebe.“ přesněji tabulku „Schémata a hodnoty z Marketing Mineru“ ? To sis napsal?
Jinak super článek 🙂
Ahoj Miloslave,
je to přesně tak jak říkáš. Marketing Miner mi připraví skupiny tak jak by je rozvrhl on. Já tyto skupiny projdu (word facet,…) a upravím je k obrazu svému (separátní tabulka) a pak s tím pracuji dál. 🙂 Kdybys neměl výstup z MMka, tak si tyto skupiny můžeš rozvrhnout sám. 🙂
Super článek Martine, Clusterizace už mi také pěkně šetří čas 🙂 co se týče klasifikace tak tam jsem ještě opatrný, stále je tam potřeba zasahovat manuálně a kontrolovat, jestli je vše správně. Už se mi stalo, že jsem odstranil i potenciální slova, které jsem mohl použít pro další účely.
Mám radost, že ti clusterizace šetří čas. 🙂
A neboj se té klasifikace, pěkně si to projít a proklikat. Je tam několik záchranných mechanizmů a rozhodně to není práce na pár minut. Stále bys nad tím měl mít plnou kontrolu a rozhoduješ co se ti smaže, protože to před tím můžeš vyfacetovat a projít.
Ahoj, Martine,
díky za návod. Super.
Po naklikání clusterizace a seřazení ručně, jsou některé řádky špatně (nejsou dle hledanosti). Chyba je i v tom, že když dám na závěr Facet by blank, tak řádky jsou střídavě prázdné a vyplněné (u clusterizovaných hodnot), místo toho, aby byly vše prázdné, když mám aplikovaný facet. Netušíš, co s tím?
Bohužel nemohu použít Tvůj skript, jelikož poučítáš pouze celkovou hledanost. Já potřebuji pracovat i s CPC. Ideálně tedy Celková hledanost, Sklik hledanost, Google Hledanost, Sklik CPC, Google CPC. Nechystáš se vylepšit?
Ahoj Lukáši,
vypadala tvoje tabulka před úpravou stejně jako je zde?
https://github.com/zatkoma/OpenRefine/tree/master/Clusterizace
Protože ten skript je napsaný tak, aby se zachoval správně pouze s touto tabulkou. Zkus si ten skript aplikovat na takto zjednodušené tabulce jestli ti bude fungovat a jestliže ano, tak je to úplně super a víme, že to funguje správně. 🙂
Pravděpodobně to bude způsobené tím, že máš překliknutý Open Refine na „records“ a ne „rows“. Zkus to prosím přepnout. To přepnutí nalezneš zde: http://prntscr.com/qace2t kdyby problém přetrvával, tak mi napiš na maila, protože budu potřebovat vidět nějaký screen. Ale věřím že by to mohlo pomoc. 🙂
Díky moc, Martine.
Přepnutí na „records“ pomohlo :-).
Jinak jsem poslal e-mail, kde je možné přiložit screeny.
Lukáš
Super návod, také moc díky. Ulehčilo a zkvalitnilo mi to práci. Palec hore.
Btw. to „apply“ jsem také hledal … 😀
Dobrý den. Ten skript na klasterizaci je zajímavé řešení.
Zajímalo by mě, zdali by šel vytvořit skript čistě na to, aby se díky němu vybrala jako hlavní vždy ta nejhledanější varianta? Ať už přímo v klasterizaci, nebo následně ve skriptu.
Abych to vysvětlil, chci docílit toho, že se nebudou ty klastrovaná slova seskupovat na jeden řádek. Chtěl bych to celé pak v excelu prezentovat trochu jinak.